PO:38:280 | Accuracy of generative artificial intelligence in risk of bias assessment using RoB 2.0 tool and extracting data in exercise therapy for chronic low back pain randomised controlled trials
Luca Carrer1, Marco Pozzati2, Dario Taborelli1, Niccolò Maschi1, Tiziano Innocenti1|3, Stefano Salvioli1 | 1DINOGMI, Università di Genova, Savona; 2Dipartimento di Neuroscienze e Riabilitazione, Università di Ferrara; 3GIMBE Foundation, Bologna, Italy
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Authors
Background. Systematic reviews are essential tools for evidence-based practice but are often time-consuming. Recent developments in artificial intelligence, including large language models such as ChatGPT-4o, offer potential to support and partially automate some processes. This study aimed to evaluate the performance of ChatGPT-4o in assessing Risk of Bias (RoB) using RoB 2.0 tool and in extracting data from randomised controlled trials (RCTs) on exercise therapy for chronic low back pain.
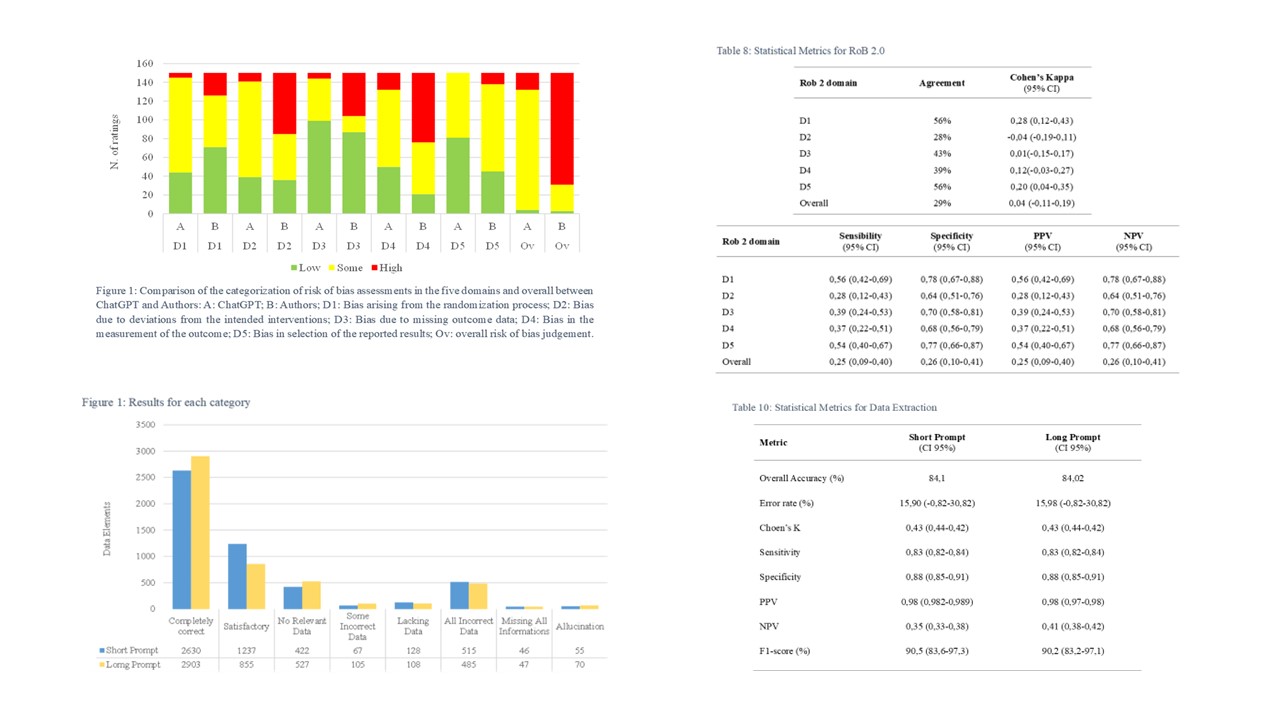
Materials and Methods. This cross-sectional comparative study included 150 RCTs previously assessed by human reviewers. ChatGPT-4o was tested in two tasks: (1) RoB assessment using a single structured prompt, compared with expert ratings across five domains and overall judgement; (2) data extraction across 34 predefined variables using both simplified and detailed prompts. Human reviewers served as the reference standard. Statistical analysis focused on Cohen’s kappa and overall accuracy, alongside sensitivity, specificity, PPV, NPV, and F1-score.
Results. Agreement between ChatGPT-4o and human reviewers for RoB assessment was low (Cohen’s κ = 0.14), with a tendency to underestimate bias. Sensitivity was 40%, while specificity and PPV were higher for low-risk classifications. For data extraction, ChatGPT-4o showed strong performance, with accuracy above 84% and F1-scores over 90% using both prompt types. Hallucinations were rare (<0.02%). Task duration was reduced from 30-50 minutes (human reviewers) to under 5 minutes with ChatGPT-4o.
Conclusions. While ChatGPT-4o showed limited reliability for RoB assessment, likely due to the interpretative complexity of the task, it performed robustly in data extraction, particularly when guided by well-structured prompts. Its high precision, speed, and low hallucination rate suggest strong potential as a secondary reviewer in systematic review workflows. Nonetheless, its application to evaluative tasks requiring critical judgement remains premature. With further development and proper human oversight, LLMs like ChatGPT-4o may help streamline systematic review processes, especially for labour-intensive, structured data extraction.

Downloads
Citations




How to Cite

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.